

AI disclosure: Banner image generated using Google Gemini and reviewed by TMC staff prior to publication.
TMC members sync data from over 70 different tools into our data warehouse. Many members also need data to be pushed from our warehouse back into those tools. If we do the math, the number of data pipelines starts to get very large, very quickly.

A selection of tools supported by TMC’s sync infrastructure. TMC members sync data between Haven and dozens of organizing, fundraising, communications, advocacy, and voter engagement platforms.
When I started at TMC six years ago, we approached each data pipeline as a unique request from the member who needed it. We would work with the member to scope exactly what they needed, consult the library of bespoke syncs that had been built for members previously to see if there was something we could repurpose, and if nothing existed, we’d build something to the exact specifications of the member requesting the work, without much consideration for scale or performance. Work was often minimally relevant for other member use cases because much of the data transformation logic lived within the sync scripts themselves.
This worked fine when TMC was a cooperative with 30 members, but as we scaled, maintaining this approach became harder. As more members began requesting small variations on existing syncs, our syncs either became Frankenstein monsters of custom business logic or multiplied into many disparate scripts, each with only slight differences and none benefiting from improvements made to the others. To address this, we began parameterizing more parts of the sync to accept user-provided inputs. This was better, but it still wasn’t completely version-controlled and didn’t solve many of our core issues around flexibility. After all, a script with 20 parameters becomes unwieldy.
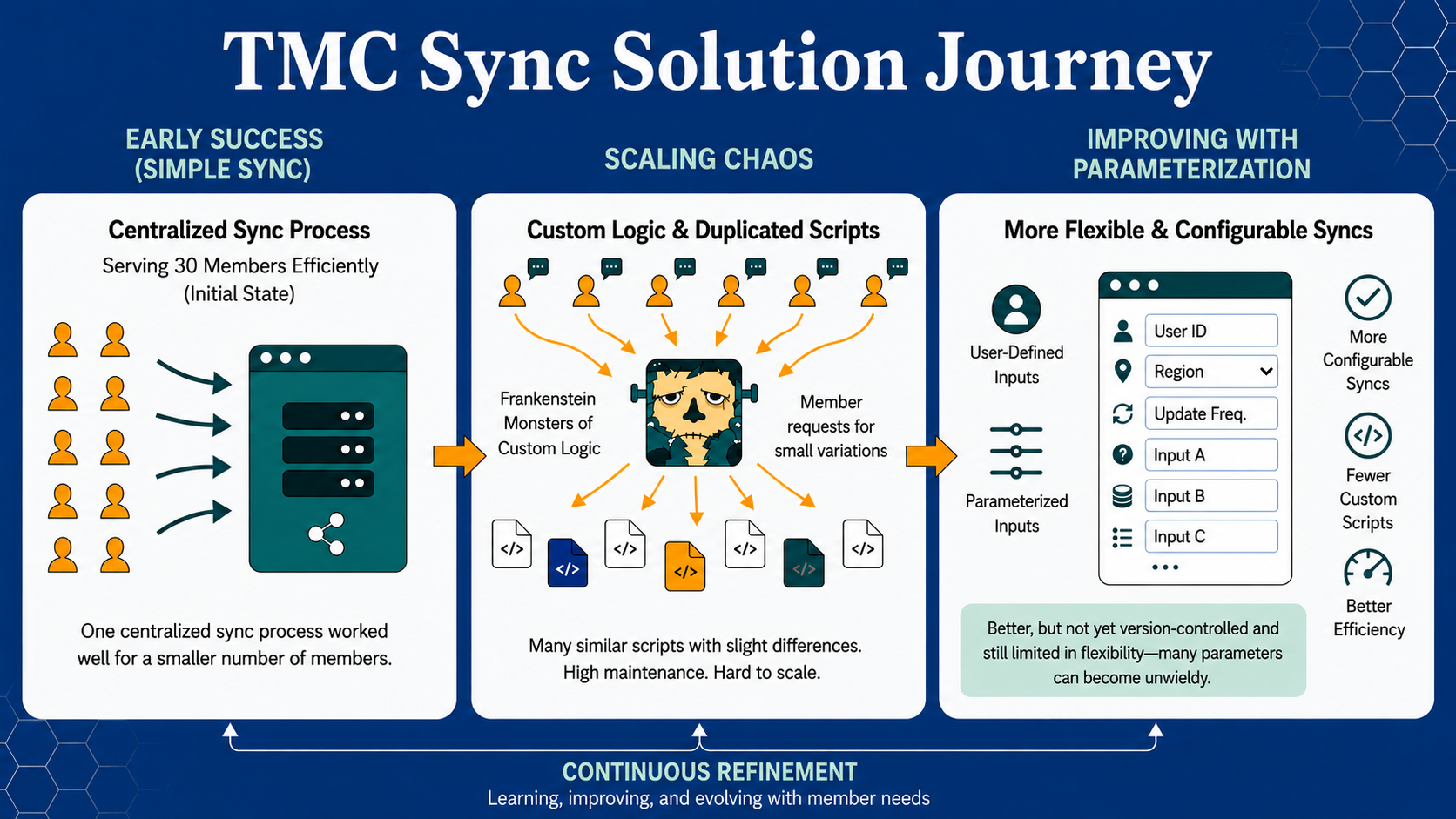
This graphic illustrates the evolution of TMC’s sync infrastructure—from a centralized sync process that worked well for a smaller cooperative, through scaling challenges caused by custom logic and duplicated scripts, to a more flexible and configurable approach using parameterized inputs. AI disclosure: Graphic generated using Google Gemini and reviewed by TMC staff prior to publication.
A New Way of Doing Things
Our migration from Redshift to Google BigQuery, along with our growth to more than 80 member organizations, created an opportunity to revisit and ultimately rebuild our approach to “sync outs”—this time from the ground up.
Our guiding principles were:
Reduce troubleshooting complexity
Reduce development time
Improve pipeline performance
Ensure continued flexibility for unique member logic
We landed on a much more modular infrastructure approach. We disentangled the data reshaping process from the data sending process and separated them into distinct steps.
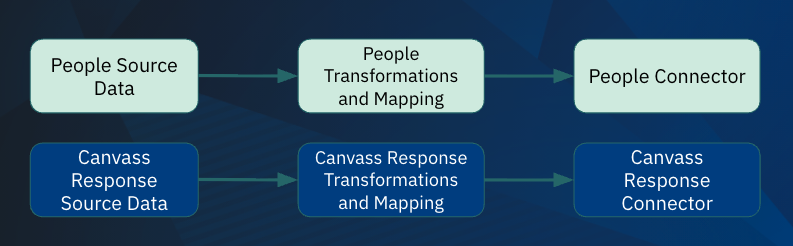
Overview of TMC's modular sync architecture. Source data is transformed and mapped before being sent to destination tools through connectors.
Data transformation now happens in SQL using dbt. This allows us to reshape data in standard ways that many members can use while also supporting highly customized transformations based on each member’s specific business logic and use cases. Does your organization need to apply the survey response “Green” to the favorite color question for everyone who was born in March? No problem—we can easily accommodate that!
We now refer to the process of sending data to a destination tool as a “connector,” and that logic lives in a nested series of Python methods. The destination is often an API, and our code is organized into classes with shared logic across all REST API connectors, for example. The logic for how we log and record every record we process is consistent across every tool sync, as is the function we use to send data to the API.
In the simplest of terms, all of our syncs now accept an input table or series of input tables. The data in those tables is already in the shape that the connector expects. The data is then sent through the connector, and information about each record is stored in log tables within each member’s Haven project. Haven is TMC's proprietary data warehouse platform, built on Google BigQuery, where member data from dozens of tools is centralized in one place.
What This Enables for TMC & Our Members
This new approach to sync outs has allowed us to more easily and quickly meet member needs. We can now stand up very complex pipelines for members for commonly used tools like EveryAction and Action Network, as well as less commonly used tools like WordPress, using the same underlying process. This means that niche or highly customized tool stacks can get a similar level of support and attention as more standard ones—enabling members to select the tools that work best for them and their programs, regardless of the tool’s popularity.
This new system has delivered immense efficiency gains internally, too. Now, adding a new connector can take as few as 10 lines of code. Because logging across all syncs is standardized, we can monitor all individual record failures in one central place, identify patterns more quickly, and troubleshoot issues faster. Improvements made to our core infrastructure can also be applied across multiple member syncs at once, reducing maintenance overhead and helping us deliver updates more efficiently.
Members can also easily request syncs for any fields supported by a vendor’s endpoints. By default, our infrastructure now supports syncing any field accepted by an API, giving members the flexibility to bring the most important data to them between systems.
Why This Work Matters Now
With tighter funding environments, continued consolidation of tools across the landscape, and the urgency of our political moment, it has become increasingly important for TMC to provide value to members through the best-in-class data and technology infrastructure. Our support is designed to remove barriers, so our members can focus on the work they do every day while opening up opportunities for greater efficiency and innovation within their systems.
TMC’s new approach to sync outs is just one example of how we continue to scale our infrastructure and meet our members where they are. It’s infrastructure designed with scalability and adaptability at its core, and we hope it enables the kind of power-building we know is incredibly necessary for the movement to thrive.
Want to learn more or get involved? Explore TMC membership here. Together, we’re laying the groundwork for a stronger, more connected progressive future.
About the author

Reta Gasser
Senior Manager, Solutions and Analytics Engineering, The Movement Cooperative
Reta Gasser (she/her) has been with TMC for six years and has seen the many ways we have moved member data to and from different systems. She is a graduate of Wesleyan University and currently resides in Denver, Colorado. In her spare time, you will likely find her reading, cooking, playing tennis, hiking, or playing mahjong.